Let's Talk, Succinctly
[2024-09-05 16:00:00 +1000]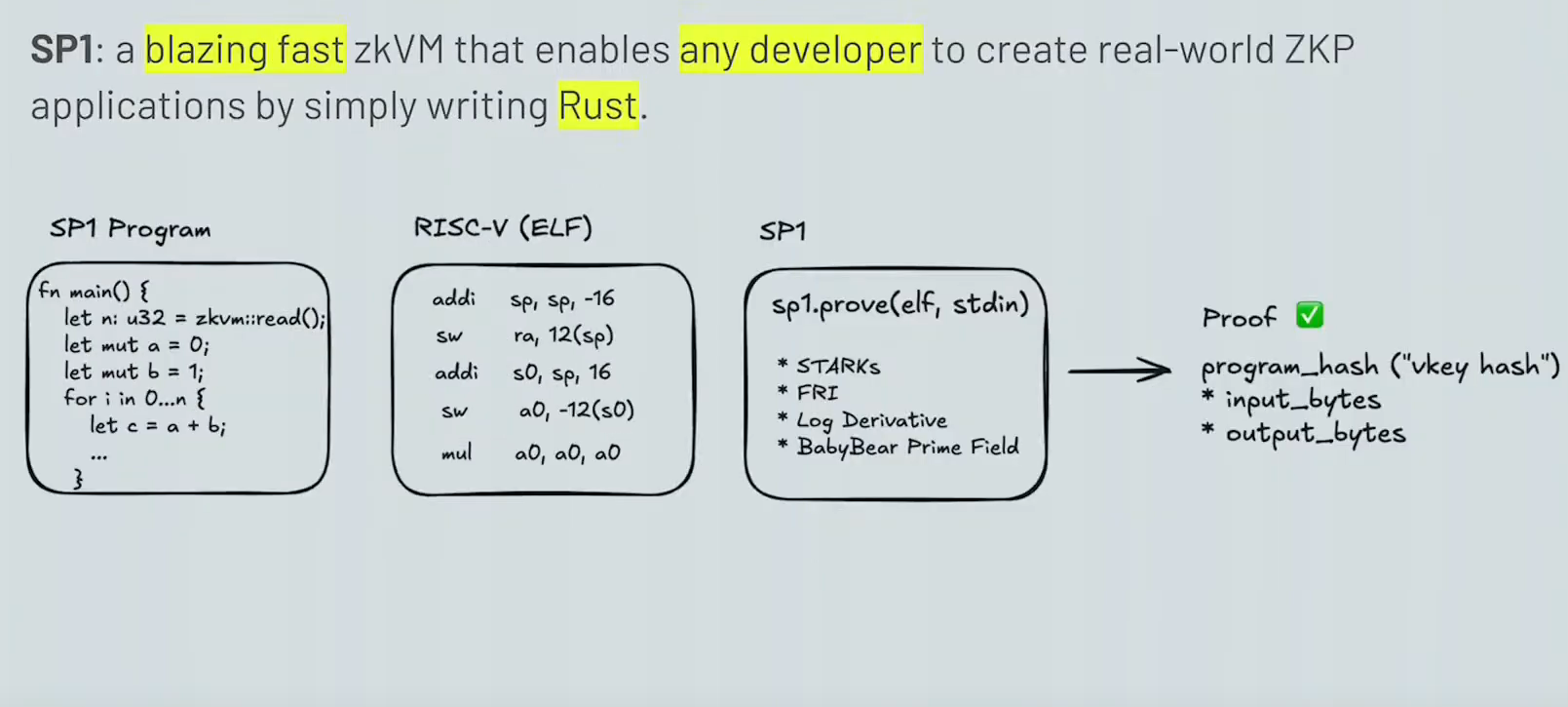
After narrowly catching the tail end of brat summer in the US, I had hoped that we could bring it to the Antipodes for our summer; although that ship has now sailed. One ship that hasn't sailed is that of ZKP-based blockchain scaling, which brings us to what I'm coining Succinct summer. Succinct takes RISC-V machine code (specifically, RV32IM) and produces proofs as to its (concrete) execution in zero-knowledge. This means that our favourite LLVM-based programming languages Just Work(TM)—Rust included. It's also very fast, and thus cheap, to use and if that's still insufficient then proof computation can be exported to a hosted platform. The Succinct stack can also verify mainnet EVM execution too.
Let's write a very simple program within the zkVM and learn stuff along the way.
Background
RISC-V
RISC-V is a family of open source RISC ISAs originally developed at UC Berkeley in 2010. Herein, I'll refer to RISC-V as both a plural and a singular noun at my convenience. It's a little endian, variably-encoded load-store register machine in 32-, 64-, and 128-bit word sizes. The RISC-V specification is structured in a modular fashion: there's a base instruction set with optional support for a variety of extensions like integer multiplication (yes that's right, you don't get that for free), floating point arithmetic, atomics, and more. Overall, it's a mature and much-loved royalty-free ISA which you can even buy consumer-grade SoCs for.
Succinct explicitly supports only a subset of the full specification (i.e., the specification with every extension enabled): RV32IM. Let's break that down:
| Component | Meaning |
|---|---|
| RV | It's RISC-V |
| 32 | Words are 32 bits wide (i.e., XLEN=32) |
| I | Everything is an integer |
| M | The integer muliplication extension ("M") is included |
SP1
SP1 is the virtual machine Succinct uses. Although, just like "regular" userspace programming, SP1 refers to two things: the VM itself and the associated runtime environment supporting it. Specifically, SP1 is a zkVM—a VM operating in zero-knowledge. Above we established that SP1 implements RV32IM, but there are some added requirements:
- Memory access must be correctly aligned
- For word opcodes (i.e.,
LWandSW) this means word-aligned (XLEN=32, remember) - For half-word opcodes (i.e.,
LH,LHU,SH) this means half-word-aligned (XLEN / 2 = 16, remember)
- For word opcodes (i.e.,
- Memory access must be bounded to $\left[\text{0x20},\text{0x78000000}\right]$
- Use
ECALLfor syscalls and ensure arguments are correctly aligned (see Succinct's documentation for specifics)
A Note on Instruction Encoding
Another aspect in which SP1 departs from RV32IM is in its instruction encoding scheme. RISC-V defines two parameters that pertain directly to handling instruction encoding: IALIGN and ILEN. RISC-V mandates that IALIGN takes on a value of either 16 or 32—nothing else. Furthermore, ILEN must take on a minimum value of 32. If an implementation only supports the base ISA (i.e., RV32I or RV64I) then it has an ILEN value of 32.
SP1 uses a custom encoding due to various ZKP-specific constraints. Namely, this avoids the need to perform instruction decoding from within the zkVM itself. It also lowers constraint complexity by storing the booleans in the Instruction type itself (essentially caching the results of a would-be decode).
/// RISC-V 32IM Instruction.
///
/// The structure of the instruction differs from the RISC-V ISA. We do not encode the instructions
/// as 32-bit words, but instead use a custom encoding that is more friendly to decode in the
/// SP1 zkVM.
#[derive(Clone, Copy, Serialize, Deserialize)]
pub struct Instruction {
/// The operation to execute.
pub opcode: Opcode,
/// The first operand.
pub op_a: u32,
/// The second operand.
pub op_b: u32,
/// The third operand.
pub op_c: u32,
/// Whether the second operand is an immediate value.
pub imm_b: bool,
/// Whether the third operand is an immediate value.
pub imm_c: bool,
}
Working With SP1
Succinct have a very clear tutorial in their documentation. This will more or less be the same except in more detail and will walkthrough the code iteratively. Instead of computing Fibonacci numbers, let's do a paraboloid.
$$ \boxed{z=f\left(x, y\right)=x^2+y^2} $$
There's nothing particularly special about this function. I chose it to demonstrate reading multiple inputs for our program rather than the one input in the Succinct guide.
$ cargo prove new spdemo
$ cd spdemo
$ tree
.
├── Cargo.lock
├── Cargo.toml
├── elf
│ └── riscv32im-succinct-zkvm-elf
├── lib
│ ├── Cargo.toml
│ └── src
│ └── lib.rs
├── LICENSE-MIT
├── program
│ ├── Cargo.lock
│ ├── Cargo.toml
│ └── src
│ └── main.rs
├── README.md
├── rust-toolchain
└── script
├── build.rs
├── Cargo.lock
├── Cargo.toml
└── src
└── bin
├── evm.rs
├── main.rs
└── vkey.rs
9 directories, 17 files
This is the default scaffold provided by Succinct. This is also in the quickstart guide but all we really need to know is that we need three crates: the program binary (spdemo-program), the prover and verifier (spdemo-script), and a common library for the both of them to share (spdemo-lib). The bulk of your application logic should live in this shared library. The actual entrypoint for SP1 should be as small as possible. This reduces attack surface and improves the performance of proof generation.
| Component | Purpose | Crate Name | Location |
|---|---|---|---|
| Shared library | Defines our application logic | spdemo-lib | lib/src/lib.rs |
| Entrypoint (or "main binary") | Connects our application to the SP1 runtime | spdemo-program | program/src/main.rs |
| Proof harness | Connects our entrypoint to the SP1 runtime (specifically, the prover and verifier) | spdemo-script | script/src/bin/main.rs |
Writing the Shared Library
So, let's write our shared library. The shared library needs to do two things at a minimum: define the outputs of our program as a Solidity ABI-encodable type and define the actual logic of what our program does.
In lib/src/lib.rs:
use alloy_sol_types::sol;
sol! {
struct PublicValuesStruct {
uint32 x;
uint32 y;
uint32 z;
}
}
/// `z = f(x, y) = x^2 + y^2`
pub fn f(x: u32, y: u32) -> u32 {
x.saturating_pow(2).saturating_add(y.saturating_pow(2))
}
Writing the SP1 Entrypoint
The SP1 entrypoint is the binary whose concrete execution will be asserted to by any eventual proofs produced by SP1. It acts as the interface between the SP1 runtime environment and our application logic (which we just defined in our shared library). The general pseudocode for what any SP1 entrypoint does is roughly as follows:
MAIN()
inputs := READ-INPUTS()
output := DO-STUFF(inputs)
commitment_bytes := SERIALISE(inputs, output)
COMMIT(commitment_bytes)
In program/src/main.rs:
#![no_main]
sp1_zkvm::entrypoint!(main);
use alloy_sol_types::SolType;
use spdemo_lib::{f, PublicValuesStruct};
pub fn main() {
let x = sp1_zkvm::io::read::<u32>();
let y = sp1_zkvm::io::read::<u32>();
let z = f(x, y);
let bytes = PublicValuesStruct::abi_encode(&PublicValuesStruct { x, y, z });
sp1_zkvm::io::commit_slice(&bytes);
}
Each successive call to sp1_zkvm::io::read retrieves an input from the SP1 runtime. We have two inputs, $x$ and $y$, so we'll have two calls. We then compute $z=x^2+y^2$ by calling our spdemo_lib::f function. We then populate our public output type, spdemo_lib::PublicValuesStruct and serialise it by ABI encoding it. Finally, we commit to these bytes by calling sp1_zkvm::io::commit_slice, writing our public output back to the SP1 runtime.
Obviously, there's some SP1-specific boilerplate present here. Namely, the entrypoint! proc macro. Essentially, this just specifies the allocator as the custom SP1 allocator and disables name mangling. It also defines the module name which the rest of the SP1 runtime uses for execution. The custom SP1 allocator doesn't do anything drastic; it simply ensures all allocations are correctly aligned (recall the added requirements that SP1 places atop RV32IM) and disables deallocation entirely.
#[macro_export]
macro_rules! entrypoint {
($path:path) => {
const ZKVM_ENTRY: fn() = $path;
use $crate::heap::SimpleAlloc;
#[global_allocator]
static HEAP: SimpleAlloc = SimpleAlloc;
mod zkvm_generated_main {
#[no_mangle]
fn main() {
super::ZKVM_ENTRY()
}
}
};
}
unsafe impl GlobalAlloc for SimpleAlloc {
unsafe fn alloc(&self, layout: Layout) -> *mut u8 {
sys_alloc_aligned(layout.size(), layout.align())
}
unsafe fn dealloc(&self, _: *mut u8, _: Layout) {}
}
Writing the Proof Harness
In script/src/bin/main.rs:
use alloy_sol_types::SolType;
use clap::Parser;
use sp1_sdk::{ProverClient, SP1Stdin};
use spdemo_lib::PublicValuesStruct;
pub const SPDEMO_ELF: &[u8] =
include_bytes!("../../../elf/riscv32im-succinct-zkvm-elf");
#[derive(Parser, Debug)]
#[clap(author, version, about, long_about = None)]
struct Args {
#[clap(long)]
execute: bool,
#[clap(long)]
prove: bool,
#[clap(long, default_value = "20")]
x: u32,
#[clap(long, default_value = "20")]
y: u32,
}
fn main() {
sp1_sdk::utils::setup_logger();
let args = Args::parse();
if args.execute == args.prove {
eprintln!("Error: You must specify either --execute or --prove");
std::process::exit(1);
}
let client = ProverClient::new();
let mut stdin = SP1Stdin::new();
stdin.write(&args.x);
stdin.write(&args.y);
println!("x: {}", args.x);
println!("y: {}", args.y);
if args.execute {
let res = client.execute(SPDEMO_ELF, stdin).run();
println!("Result: {res:?}");
let (output, report) = res.unwrap();
println!("Program executed successfully");
let decoded =
PublicValuesStruct::abi_decode(output.as_slice(), true).unwrap();
let PublicValuesStruct { x, y, z } = decoded;
println!("x: {}", x);
println!("y: {}", y);
println!("z: {}", z);
let expected_z = spdemo_lib::f(x, y);
assert_eq!(z, expected_z);
println!("Value is correct!");
println!("Number of cycles: {}", report.total_instruction_count());
} else {
let (pk, vk) = client.setup(SPDEMO_ELF);
let proof = client
.prove(&pk, stdin)
.run()
.expect("failed to generate proof");
println!("Successfully generated proof!");
client.verify(&proof, &vk).expect("failed to verify proof");
println!("Successfully verified proof!");
}
}
Generating a Proof
When we invoke the proof harness in execution mode (i.e., with the --execute flag), we get the expected output:
$ RUST_LOG=info cargo run --release -- --execute
x: 20
y: 20
2024-08-30T23:02:44.465116Z INFO execute: clk = 0 pc = 0x2012f4
2024-08-30T23:02:44.470979Z INFO execute: close time.busy=10.2ms time.idle=8.28µs
Result: Ok((SP1PublicValues { buffer: Buffer { data: [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 20, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 20, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 3, 32], ptr: 0 } }, ExecutionReport { opcode_counts: {MUL: 7, SB: 54, BEQ: 19, LW: 602, ECALL: 22, JALR: 48, BNE: 16, SLTU: 12, AND: 448, MULHU: 2, SUB: 21, SW: 507, OR: 1297, ADD: 1847, LBU: 142, SRL: 1373, SLL: 1281, BGEU: 8, AUIPC: 29, XOR: 1410, BLTU: 48}, syscall_counts: {WRITE: 1, COMMIT_DEFERRED_PROOFS: 8, HALT: 1, HINT_LEN: 2, COMMIT: 8, HINT_READ: 2} }))
Program executed successfully
x: 20
y: 20
z: 800
Value is correct!
Number of cycles: 9193
Now that we've established correct execution (of each of the shared library, entrypoint, and proof harness) we can finally generate a proof! To do so, we invoke the proof harness in proving mode (i.e., with the --prove flag).
$ RUST_LOG=info cargo run --release -- --prove
x: 20
y: 20
2024-08-30T23:09:20.100987Z INFO prove_core: clk = 0 pc = 0x2012f4
2024-08-30T23:09:20.117032Z INFO prove_core: clk = 0 pc = 0x2012f4
2024-08-30T23:09:26.785323Z INFO prove_core: clk = 0 pc = 0x2012f4
2024-08-30T23:09:56.491078Z INFO prove_core: execution report (totals): total_cycles=9193, total_syscall_cycles=22
2024-08-30T23:09:56.491156Z INFO prove_core: execution report (opcode counts):
2024-08-30T23:09:56.491185Z INFO prove_core: 1847 add
2024-08-30T23:09:56.491190Z INFO prove_core: 1410 xor
2024-08-30T23:09:56.491193Z INFO prove_core: 1373 srl
2024-08-30T23:09:56.491199Z INFO prove_core: 1297 or
2024-08-30T23:09:56.491203Z INFO prove_core: 1281 sll
2024-08-30T23:09:56.491207Z INFO prove_core: 602 lw
2024-08-30T23:09:56.491211Z INFO prove_core: 507 sw
2024-08-30T23:09:56.491215Z INFO prove_core: 448 and
2024-08-30T23:09:56.491219Z INFO prove_core: 142 lbu
2024-08-30T23:09:56.491223Z INFO prove_core: 54 sb
2024-08-30T23:09:56.491228Z INFO prove_core: 48 bltu
2024-08-30T23:09:56.491232Z INFO prove_core: 48 jalr
2024-08-30T23:09:56.491236Z INFO prove_core: 29 auipc
2024-08-30T23:09:56.491240Z INFO prove_core: 22 ecall
2024-08-30T23:09:56.491244Z INFO prove_core: 21 sub
2024-08-30T23:09:56.491248Z INFO prove_core: 19 beq
2024-08-30T23:09:56.491252Z INFO prove_core: 16 bne
2024-08-30T23:09:56.491257Z INFO prove_core: 12 sltu
2024-08-30T23:09:56.491261Z INFO prove_core: 8 bgeu
2024-08-30T23:09:56.491265Z INFO prove_core: 7 mul
2024-08-30T23:09:56.491269Z INFO prove_core: 2 mulhu
2024-08-30T23:09:56.491274Z INFO prove_core: execution report (syscall counts):
2024-08-30T23:09:56.491297Z INFO prove_core: 8 commit
2024-08-30T23:09:56.491302Z INFO prove_core: 8 commit_deferred_proofs
2024-08-30T23:09:56.491306Z INFO prove_core: 2 hint_len
2024-08-30T23:09:56.491310Z INFO prove_core: 2 hint_read
2024-08-30T23:09:56.491313Z INFO prove_core: 1 halt
2024-08-30T23:09:56.491317Z INFO prove_core: 1 write
2024-08-30T23:09:56.495561Z INFO prove_core: summary: cycles=9193, e2e=36.393873299s, khz=0.25, proofSize=3258660
2024-08-30T23:09:56.496574Z INFO prove_core: close time.busy=36.3s time.idle=69.9ms
Successfully generated proof!
2024-08-30T23:09:56.963866Z INFO verify: close time.busy=464ms time.idle=3.15µs
Successfully verified proof!
Included in the output of the prover is an execution report that's rather detailed. Notably, we have a tally of each RV32IM opcode encountered during execution as well as a tally of each syscall made by the resident program. Note that the sum of all of the syscalls is exactly the number of ECALL opcodes in the above tally1. Finally, we have a summary of the clock cycles, end-to-end proof time, the clock rate, and the size of the generated proof.
The Case for the Succinct Stack
Tooling
The Succinct tooling is easily the smoothest that I've encountered to date. Obviously, this is critically important in attracting application developers to a computing platform. I don't feel it necessary to explain, nor defend the importance of, developer experience in this piece. Installation is smooth (although there are admittedly some rough edges as of the time of writing). If you're on a system with a compatible version of glibc, installation from a prebuilt binary is fairly straightforward:
$ curl -L https://sp1.succinct.xyz | bash
$ sp1up
Otherwise, building from source is also relatively painless (I'm a Debian user so I'm fairly used to it!). Ignoring installation (which is certainly a fairly low bar to clear), the actual workflow is also fairly seamless, which means iteration speed can remain high. I'm a fan of the cargo integration in particular.
Performance
Succinct's (GPU-accelerated) prover produces order-of-magnitude cheaper proofs on real Ethereum blocks. Additionally, any computation required by a SP1-driven application can be outsourced to the Succinct Prover Network to access this performance remotely and in an on-demand fashion.
RSP
One particularly impressive application of SP1 is in zero-knowledge verification of true Ethereum blocks. A technical demonstration of this was presented very recently at Frontiers 2024, with rsp correctly attesting to the correct execution of mainnet blocks #20528720 - #20528725.
Summary
SP1 is a performant and "clean" zkVM running a (slightly modified) RISC-V ISA implemented in Rust by Succinct Labs. Succinct offer a hosted compute solution, Succinct Prover Network. At Frontiers 2024, Succinct demonstrated verification of real Ethereum blocks, costing to the order of a cent.
Further Reading
Obviously, the relevant source material for RISC-V (i.e., the specification and official website) and Succinct (i.e., the SP1 source code, the rsp source code, their documentation, and their blog). This article from CNX Software is a good treatment of the RISC-V base ISAs and their extensions—as is this Stack Overflow thread.
For zero-knowledge blockchain scaling more generally, essentially the entire body of writing by Vitalik Buterin is, of course, unrivalled. In particular, this article provides an excellent treatment of co-processor-based architectures and this one provides a very important consideration of the implications of a multi-zkVM world for Ethereum (notably, Succinct is also directly mentioned). This collection of papers by Ingonyama is also very good. Obviously, this is not intended to be an exhaustive literary review of (the extremely broad topic of) ZKP-based blockchain scaling.
Also note that this is the same as the number of syscall cycles. This is due to both the bijectivity of the ECALL-syscall relation and that ECALL consumes exactly one clock cycle.