Minimising Exchange Latency in the Cloud
[2026-05-28 10:00:00 +1000]Trading, at a high level, is an extremely broad set of activities but ultimately boils down to moving information around. This information often has an incredibly short shelf life. For this reason, trading (in any form) benefits from speed. When we are trading with computers, our speed is overwhelmingly dominated by communicating with our counterparties via an exchange. As such, we want to get our computer as close as we reasonably can to the exchange's computer. Ideally, this would be relatively straightforward, but our world is far from ideal. In reality, there are complexities like CDNs, load balancers, the architecture of the exchange's infrastructure, which transport protocol we're using, and many more.
In this tutorial, we'll progress through a few different approaches to measuring the network latency that we actually experience when interacting with an exchange, increasing the complexity of each approach only when strictly necessary to improve the accuracy of our measurements. We'll automate the process using a tool that I've written, ringer.
Homework
Firstly, some exchanges explicitly state where their computers are located. This is certainly not the typical posture, but there are some notable examples of exchanges being very transparent about this. Bybit, for instance, claims to be hosted in ap-southeast-1 (specifically the apse1-az2 and apse1-az3 Availability Zones) as part of their official documentation.
If the exchange doesn't straight up tell us where they are, we can still find out through plenty of alternative channels. For crypto specifically, this will often be on Discord servers or in Telegram channels (official or otherwise). Good old-fashioned research on the web still pays dividends even in 2026: consider this Reuters coverage of a Binance outage that they directly attribute to downtime for AWS Tokyo (i.e., ap-northeast-1). Following this lead, I was able to find this article narrowing it down even further to a specific AZ: apne1-az4.
Now, Binance's cloud hosting location is perhaps the worst-kept secret in all of crypto. Regardless, the point is that due diligence can often allow us to corroborate the results of our own latency work or even bypass it altogether.
Pinging
Naively, our initial strategy might be to simply ping the exchange's API endpoint. Something like this,
FIND-MINIMUM-LATENCY(target, available_regions)
min_latency := INFINITY
best_region := NULL
for region in available_region
START-INSTANCE(region)
curr_latency := PING(target)
if curr_latency <= min_latency
min_latency := curr_latency
best_region := region
return (best_region, min_latency)
The problem with this solution is that ping(8) simply sends an ICMP echo request (i.e., control message type 0x81) to the remote host. This is fine for getting the latency to a "normal" computer but will not work for our task. There are two reasons for this: exchanges treat ICMP traffic differently to TCP traffic and there are network intermediaries between us and the exchange (namely CDN edge gateways and load balancers). For the latter issue, when we ping the exchange our ICMP packets will first hit the CDN's edge node; the response that we receive is from the edge node itself rather than the CDN application layer — and this is assuming that the CDN does not just immediately drop our request.
As a concrete example, let's consider what pinging Bybit's API looks like from my home network.
$ ping -c 10 api.bybit.com
PING d3d4ij29qlbhtu.cloudfront.net (18.155.216.88) 56(84) bytes of data.
64 bytes from server-18-155-216-88.bne50.r.cloudfront.net (18.155.216.88): icmp_seq=1 ttl=248 time=2.81 ms
64 bytes from server-18-155-216-88.bne50.r.cloudfront.net (18.155.216.88): icmp_seq=2 ttl=248 time=3.89 ms
64 bytes from server-18-155-216-88.bne50.r.cloudfront.net (18.155.216.88): icmp_seq=3 ttl=248 time=5.44 ms
64 bytes from server-18-155-216-88.bne50.r.cloudfront.net (18.155.216.88): icmp_seq=4 ttl=248 time=4.54 ms
64 bytes from server-18-155-216-88.bne50.r.cloudfront.net (18.155.216.88): icmp_seq=5 ttl=248 time=5.75 ms
64 bytes from server-18-155-216-88.bne50.r.cloudfront.net (18.155.216.88): icmp_seq=6 ttl=248 time=4.51 ms
64 bytes from server-18-155-216-88.bne50.r.cloudfront.net (18.155.216.88): icmp_seq=7 ttl=248 time=3.42 ms
64 bytes from server-18-155-216-88.bne50.r.cloudfront.net (18.155.216.88): icmp_seq=8 ttl=248 time=4.18 ms
64 bytes from server-18-155-216-88.bne50.r.cloudfront.net (18.155.216.88): icmp_seq=9 ttl=248 time=3.77 ms
64 bytes from server-18-155-216-88.bne50.r.cloudfront.net (18.155.216.88): icmp_seq=10 ttl=248 time=3.39 ms
--- d3d4ij29qlbhtu.cloudfront.net ping statistics ---
10 packets transmitted, 10 received, 0% packet loss, time 9017ms
rtt min/avg/max/mdev = 2.807/4.170/5.752/0.872 ms
There is no way that I actually live anywhere near 5ms away from Bybit's API endpoint. These response times are from my closest2 CloudFront edge node. It's worth noting that at no point in the above output from ping(8) did the hostname ever resolve to anything Bybit-specific, which is extremely telling.
Shaking Hands
A better method is to connect to the exchange server. The minimal way to do this is to time how long it takes to complete a TCP handshake. The algorithm is essentially the same as the one above: for each AWS3 cloud region, perform a full TCP handshake and record how long it takes for this handshake to complete. Essentially, execute this program from each AWS region:
import socket, time, json
host = "api.bybit.com"
port = 443
samples = 10
rtts = []
for _ in range(samples):
t0 = time.perf_counter()
try:
s = socket.create_connection((host, port), timeout=2)
s.close()
rtts.append((time.perf_counter() - t0) * 1000)
print(rtts[-1])
except OSError:
pass
Now, actually doing the deployment programmatically is somewhat more involved. What we can do is have our payload program write some JSON-formatted results data to an S3 bucket and then associate each result set with the region that it's from — which is what ringer does. Using ringer requires some prerequisite setup. This is mostly having an AWS account that's either funded or has free-tier credits and then configuring IAM roles and permissions. Assuming that you've met these necessary requirements, then it's rather straightforward to perform this TCP benchmark:
$ uv run ringer.py \
--target api.bybit.com \
--port 443 \
--bucket latency-sweep-results
Probing 18 regions → api.bybit.com:443 (tcp)
All instances launched — waiting for results...
[ap-southeast-2] p50=1.14ms
[ap-southeast-4] p50=0.89ms
[ap-southeast-1] p50=1.21ms
[ap-northeast-1] p50=2.91ms
[ca-central-1] p50=1.50ms
[eu-west-2] p50=1.04ms
[us-west-1] p50=0.75ms
[sa-east-1] p50=1.08ms
[ap-northeast-2] p50=0.59ms
[us-east-2] p50=1.46ms
[eu-west-3] p50=1.07ms
[ap-northeast-3] p50=1.03ms
[ap-south-1] p50=1.17ms
[eu-north-1] p50=3.39ms
[eu-west-1] p50=0.91ms
[us-west-2] p50=5.58ms
[eu-central-1] p50=1.18ms
All instances terminated — no more results coming.
Warning: 1 region(s) never reported results
Region min p50 p99 samples
-----------------------------------------------------------------
ap-northeast-2 0.44ms 0.59ms 6.85ms 100
us-west-1 0.56ms 0.75ms 12.90ms 100
ap-southeast-4 0.74ms 0.89ms 28.58ms 100
eu-west-1 0.80ms 0.91ms 2005.28ms 100
ap-northeast-3 0.82ms 1.03ms 23.38ms 100
eu-west-2 0.75ms 1.04ms 5.59ms 100
eu-west-3 0.97ms 1.07ms 4.50ms 100
sa-east-1 0.89ms 1.08ms 5.59ms 100
ap-southeast-2 0.91ms 1.14ms 9.47ms 100
ap-south-1 0.92ms 1.17ms 4.54ms 100
eu-central-1 0.94ms 1.18ms 6.26ms 100
ap-southeast-1 0.83ms 1.21ms 6.83ms 100
us-east-2 1.13ms 1.46ms 10.30ms 100
ca-central-1 0.82ms 1.50ms 6.31ms 100
ap-northeast-1 2.11ms 2.91ms 1050.68ms 100
eu-north-1 3.09ms 3.39ms 8.89ms 100
us-west-2 5.20ms 5.58ms 2055.84ms 100
Best region: ap-northeast-2 (p50=0.59ms)
This approach should be surprising to us: recall from our research above that Bybit claims to be hosted in ap-southeast-1 yet ringer reports that ap-northeast-2 is the optimal region. The problem with this approach is similar to the problem with pinging: CDNs. When we complete this TCP handshake, we're actually establishing a connection to the edge node. This edge node does a few things (like TLS termination) and then forwards (certain) traffic to the backend application layer.
Actual Connection
A reliable way to ensure that we're actually talking to the real exchange is to pull live order book data from it. After all, no CDN can cache nor predict prices4. Fortunately, ringer also supports this approach:
$ uv run --with boto3 python3 ringer.py \
--target stream.bybit.com \
--port 443 \
--bucket latency-sweep-results \
--ws \
--ws-path /v5/public/spot \
--subscribe '{"op":"subscribe","args":["orderbook.1.BTCUSDT"]}'
Probing 18 regions → stream.bybit.com:443 (websocket)
All instances launched — waiting for results...
[ap-southeast-1] p50=23.64ms msg_p50=2.09ms msg_p99=6.95ms
[ap-south-1] p50=201.48ms msg_p50=61.81ms msg_p99=69.44ms
[ap-northeast-1] p50=222.09ms msg_p50=69.06ms msg_p99=96.48ms
[ap-southeast-4] p50=322.55ms msg_p50=102.68ms msg_p99=108.01ms
[ap-northeast-2] p50=220.59ms msg_p50=68.12ms msg_p99=90.87ms
[ap-northeast-3] p50=246.55ms msg_p50=77.23ms msg_p99=115.81ms
[ap-southeast-2] p50=293.87ms msg_p50=92.77ms msg_p99=102.11ms
[eu-central-1] p50=486.98ms msg_p50=157.06ms msg_p99=171.56ms
[eu-west-3] p50=484.66ms msg_p50=156.81ms msg_p99=179.80ms
[eu-west-2] p50=507.50ms msg_p50=164.26ms msg_p99=175.16ms
[eu-west-1] p50=533.41ms msg_p50=172.69ms msg_p99=210.73ms
[us-west-2] p50=501.22ms msg_p50=159.68ms msg_p99=170.28ms
[eu-north-1] p50=546.71ms msg_p50=176.40ms msg_p99=190.13ms
[us-west-1] p50=521.25ms msg_p50=168.92ms msg_p99=189.65ms
[us-east-2] p50=640.52ms msg_p50=207.31ms msg_p99=219.48ms
[ca-central-1] p50=693.62ms msg_p50=226.01ms msg_p99=244.68ms
[sa-east-1] p50=997.22ms msg_p50=326.46ms msg_p99=338.76ms
All instances terminated — no more results coming.
Region hs_min hs_p50 hs_p99 msg_p50 msg_p99 samples
-------------------------------------------------------------------------------------
ap-southeast-1 18.72ms 23.64ms 41.58ms 2.09ms 6.95ms 100
ap-south-1 194.25ms 201.48ms 265.11ms 61.81ms 69.44ms 100
ap-northeast-2 215.11ms 220.59ms 257.95ms 68.12ms 90.87ms 100
ap-northeast-1 217.05ms 222.09ms 252.72ms 69.06ms 96.48ms 100
ap-northeast-3 239.85ms 246.55ms 433.92ms 77.23ms 115.81ms 100
ap-southeast-2 289.06ms 293.87ms 340.18ms 92.77ms 102.11ms 100
ap-southeast-4 316.13ms 322.55ms 407.47ms 102.68ms 108.01ms 100
eu-west-3 451.92ms 484.66ms 552.24ms 156.81ms 179.80ms 100
eu-central-1 484.04ms 486.98ms 602.17ms 157.06ms 171.56ms 100
us-west-2 490.79ms 501.22ms 533.51ms 159.68ms 170.28ms 100
eu-west-2 476.42ms 507.50ms 539.66ms 164.26ms 175.16ms 100
us-west-1 512.56ms 521.25ms 544.22ms 168.92ms 189.65ms 100
eu-west-1 499.69ms 533.41ms 565.09ms 172.69ms 210.73ms 100
eu-north-1 542.41ms 546.71ms 587.43ms 176.40ms 190.13ms 100
us-east-2 604.84ms 640.52ms 697.95ms 207.31ms 219.48ms 100
ca-central-1 664.43ms 693.62ms 764.59ms 226.01ms 244.68ms 100
sa-east-1 967.92ms 997.22ms 1031.48ms 326.46ms 338.76ms 100
Best region: ap-southeast-1 (first_msg_p50=2.09ms)
This result, ap-southeast-1, is consistent with what we discovered above during our research phase; our 99th percentile time-to-first-message is 6.95ms, which agrees with our intuition.
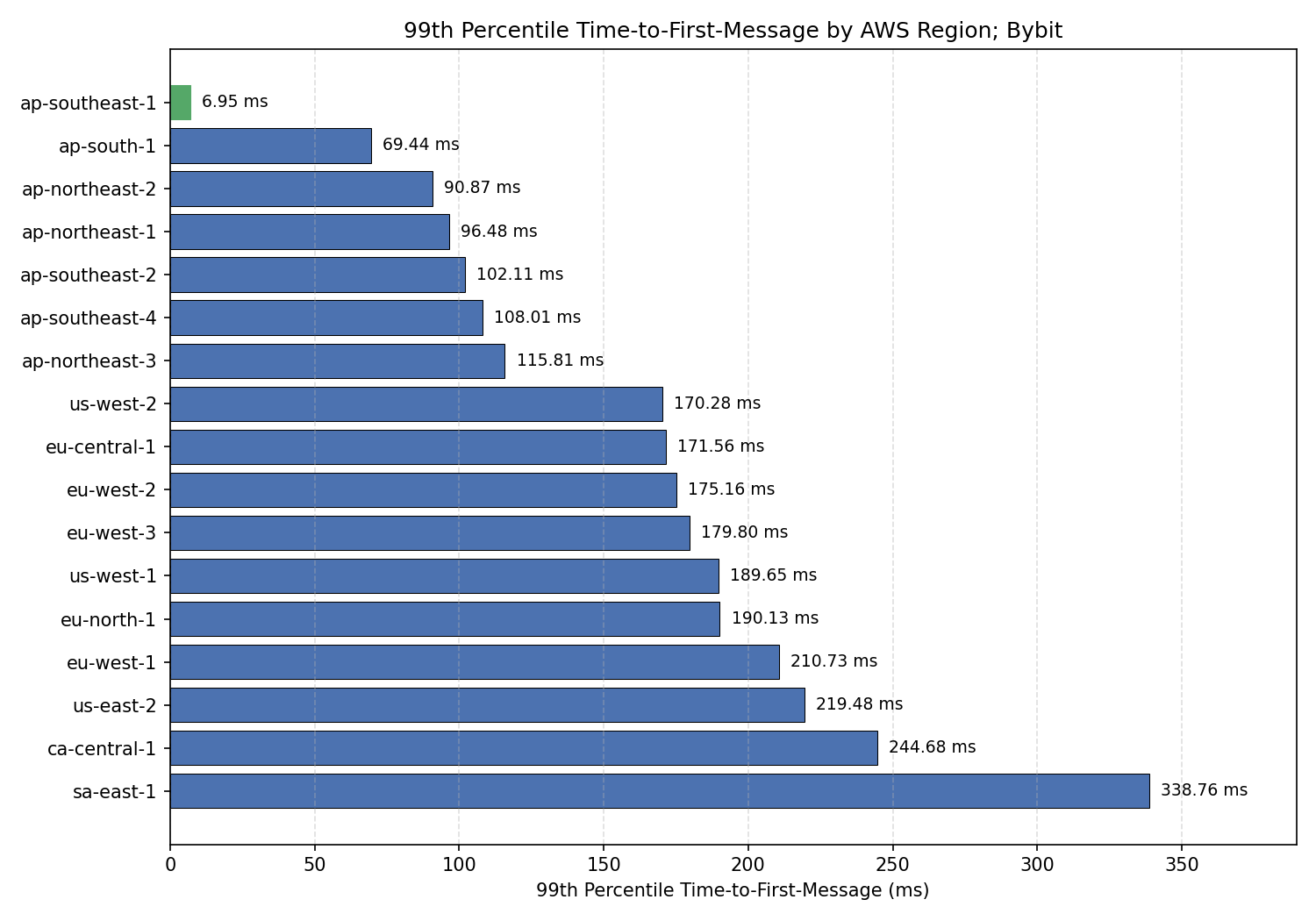
msg_p99) for BybitConclusion
This search task is fairly easy to automate and could drastically reduce your latency to the exchange that you're trading on. To drive the point home, if we were trading on Bybit and had decided to host in us-east-2 (Ohio), then we'd be over 31 times slower5 than our competition in ap-southeast-1 (Singapore) — and this does not even take into account other speed advantages that they may have.
It's worth noting that the metric we've used throughout, time-to-first-message, isn't actually that useful for real production trading infrastructure; however, it suffices for determining where to put our computer. In a real setting, we likely care much more about our tick-to-trade latency. Additionally, there is a lot more work that goes into latency optimisation and what we've covered here is simply the first6 step in a long process.
Bibliography
[1] J. Postel, "Internet Control Message Protocol," RFC 792, Sep. 1981. [Online]. Available: https://datatracker.ietf.org/doc/html/rfc792. [Accessed: May 27, 2026].
[2] apalrd, "Starting my own Content Delivery Network," YouTube, May 15, 2026. [Online]. Available: https://www.youtube.com/watch?v=LCJIQufZeeg. [Accessed: May 27, 2026].
[3] Bybit, "Where are Bybit's Servers Located?" in Bybit API Documentation, Bybit. [Online]. Available: https://bybit-exchange.github.io/docs/faq#where-are-bybits-servers-located. [Accessed: May 27, 2026].
[4] Amazon Web Services, "Regions and Zones," in Amazon EC2 User Guide. [Online]. Available: https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/using-regions-availability-zones.html#concepts-availability-zones. [Accessed: May 27, 2026].
[5] Reuters, "Binance Services Start to Recover After Network Interruption," Reuters, Apr. 15, 2025. [Online]. Available: https://www.reuters.com/technology/binance-services-start-recover-after-network-interruption-2025-04-15. [Accessed: May 27, 2026].
[6] Data Center Dynamics, "Network Issue at AWS Data Center Brings Down Crypto Exchanges," Data Center Dynamics, Feb. 11, 2026. [Online]. Available: https://www.datacenterdynamics.com/en/news/network-issue-at-aws-data-center-brings-down-crypto-exchanges. [Accessed: May 27, 2026].
[7] J. Albers, M. Cucuringu, S. Howison, and A. Y. Shestopaloff, "The Good, the Bad, and Latency: Exploratory Trading on Bybit and Binance," SSRN Working Paper 4677989, Nov. 2024. [Online]. Available: https://papers.ssrn.com/sol3/papers.cfm?abstract_id=4677989. [Accessed: May 27, 2026].
[8] Databento, "What is Tick-to-Trade Latency?" in Databento Microstructure Guide, Databento, Inc. [Online]. Available: https://databento.com/microstructure/tick-to-trade. [Accessed: May 27, 2026].
The Internet Control Message Protocol (ICMP) is specified in RFC 792 and is one of the oldest Internet protocols still in widespread use today. 2: Technically the "cheapest route", but this is usually the same as physical proximity these days. The actual specifics of this involve traversing the BGP rabbit hole. 3: You needn't choose AWS as the cloud provider and should, in fact, choose the provider which the target server is hosted with. With this being said, virtually every serious exchange is going to be hosted on AWS. I've chosen AWS for this article because it is ubiquitous, has the largest set of available regions, and exposes programmatic access to enable us to automate our search. 4: If you're aware of one that does, then I'd like to invest. 5: I'm comparing the 99th percentile WebSocket handshake times. 6: And likely the step with the largest improvement!